
Types de visualisations et quand les utiliser
Voici une liste de quelques types de visualisations courantes, ainsi que des exemples de code pour les générer en utilisant la bibliothèque Python Matplotlib.
Comment installer Matplotlib ?
Sur Python :
Ouvrez votre invite de commande ou terminal
Tapez la commande suivante : pip install matplotlib
Appuyez sur Entrée et attendez que l’installation soit terminée
Sur Anaconda :
Ouvrez l’invite de commande Anaconda ou le terminal Anaconda
Tapez la commande suivante : conda install matplotlib
Appuyez sur Entrée et attendez que l’installation soit terminée
Après avoir installé Matplotlib, on peut commencer à coder, voici quelques codes à utiliser afin de visualiser sur Python.
Personnellement, je vais utiliser Jupyter Notebook via Anaconda.
1. Graphiques à barres :
import matplotlib.pyplot as plt
# Données
categories = [‘Catégorie 1’, ‘Catégorie 2’, ‘Catégorie 3’]
values = [50, 30, 70]
# Création du graphique
plt.bar(categories, values)
# Ajout d’étiquettes
plt.xlabel(‘Catégories’)
plt.ylabel(‘Valeurs’)
plt.title(‘Graphique à barres’)
plt.show()
Les graphiques à barres sont utiles pour comparer des valeurs discrètes. Ils sont particulièrement utiles lorsque vous souhaitez mettre en évidence les différences entre des catégories ou des groupes.
Exemple, depuis mon interface Jupyter :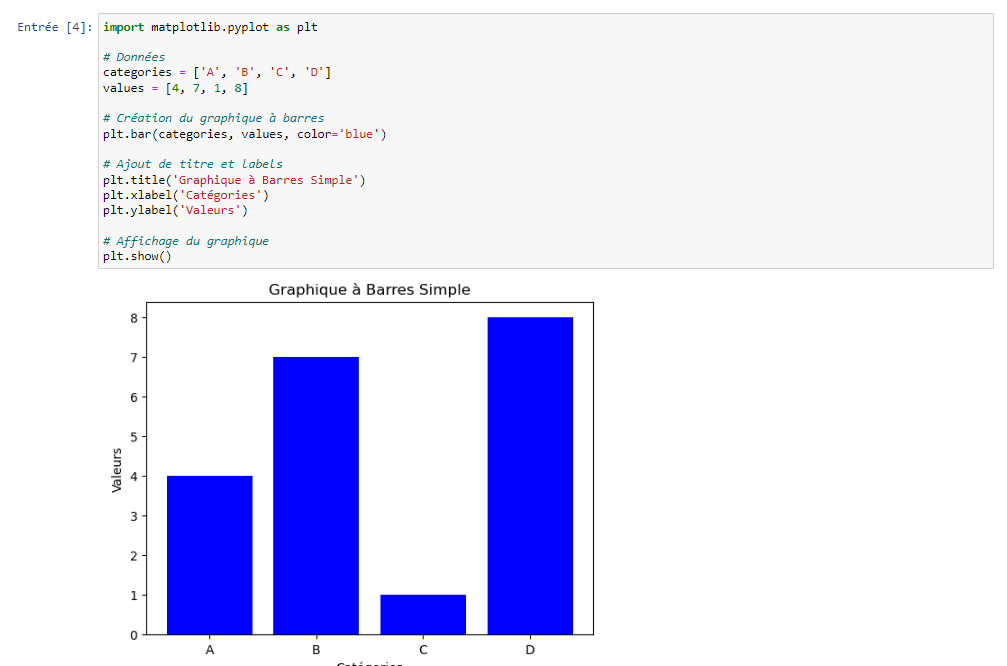
2.Diagrammes en camembert :
import matplotlib.pyplot as plt
# Données
categories = [‘Catégorie 1’, ‘Catégorie 2’, ‘Catégorie 3’]
values = [50, 30, 20]
# Création du diagramme en camembert
plt.pie(values, labels=categories)
# Ajout d’étiquettes
plt.title(‘Diagramme en camembert’)
plt.show()
Les diagrammes en camembert sont utiles pour montrer les proportions d’un tout. Ils sont particulièrement utiles lorsque vous souhaitez montrer la répartition d’une variable catégorielle.
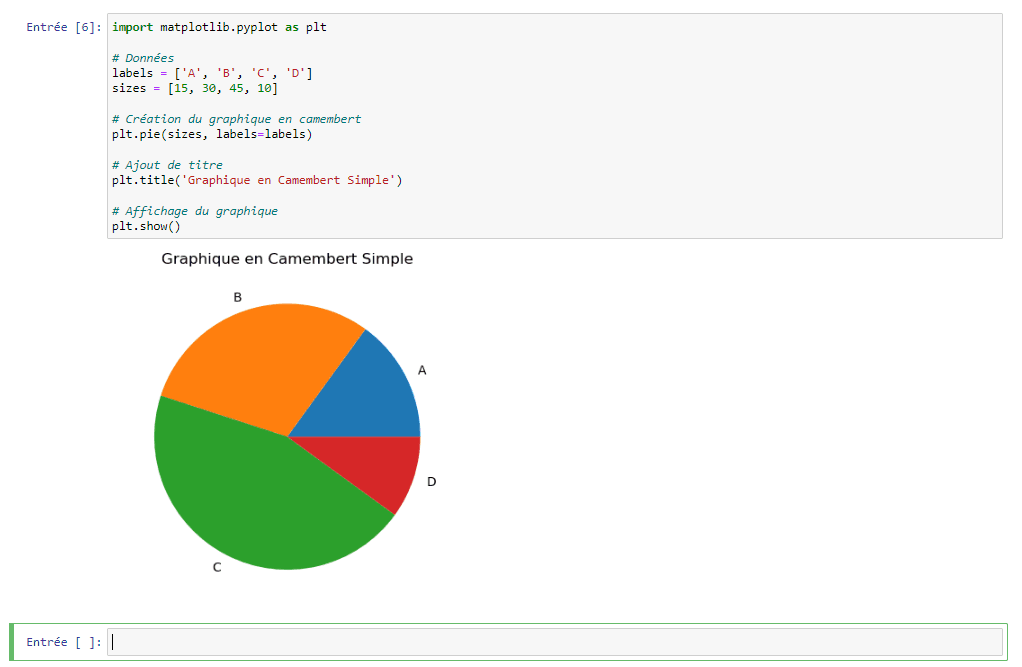
3.Histogrammes :
import matplotlib.pyplot as plt
import numpy as np
# Données
data = np.random.normal(0, 1, 1000)
# Création de l’histogramme
plt.hist(data)
# Ajout d’étiquettes
plt.xlabel(‘Valeurs’)
plt.ylabel(‘Fréquence’)
plt.title(‘Histogramme’)
plt.show()
Les histogrammes sont utiles pour montrer la distribution d’une variable continue. Ils sont particulièrement utiles lorsque vous souhaitez montrer la fréquence ou la densité des données.
Exemple :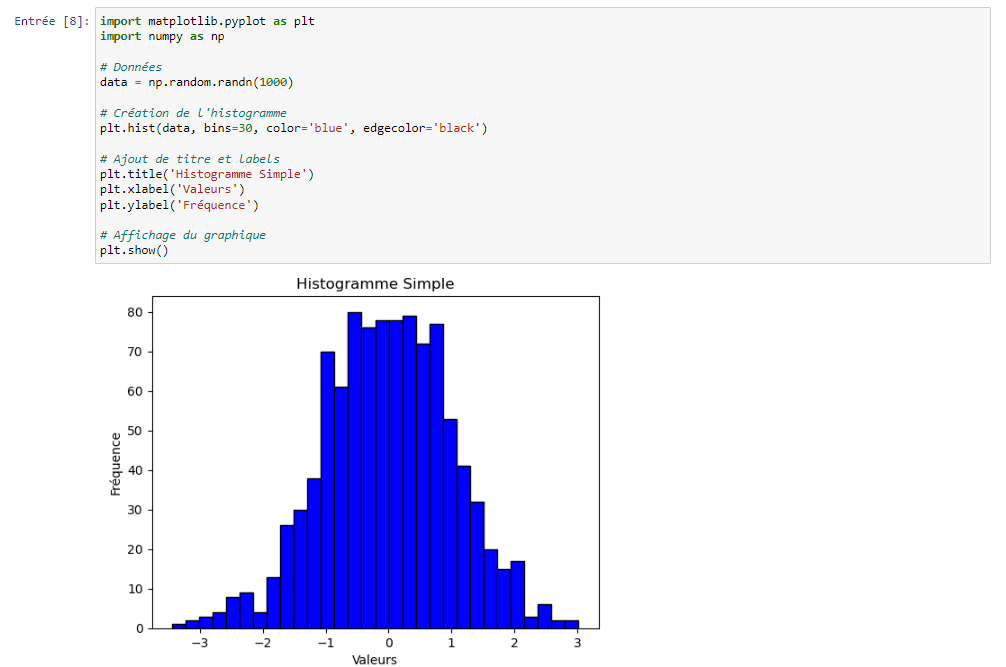
4.Nuages de points :
import matplotlib.pyplot as plt
import numpy as np
# Données
x = np.linspace(0, 10, 100)
y = np.sin(x)
# Création du nuage de points
plt.scatter(x, y)
# Ajout d’étiquettes
plt.xlabel(‘x’)
plt.ylabel(‘y’)
plt.title(‘Nuage de points’)
plt.show()
Les nuages de points sont utiles pour montrer la relation entre deux variables continues. Ils sont particulièrement utiles lorsque vous souhaitez montrer la corrélation ou la tendance entre deux variables.
Exemple :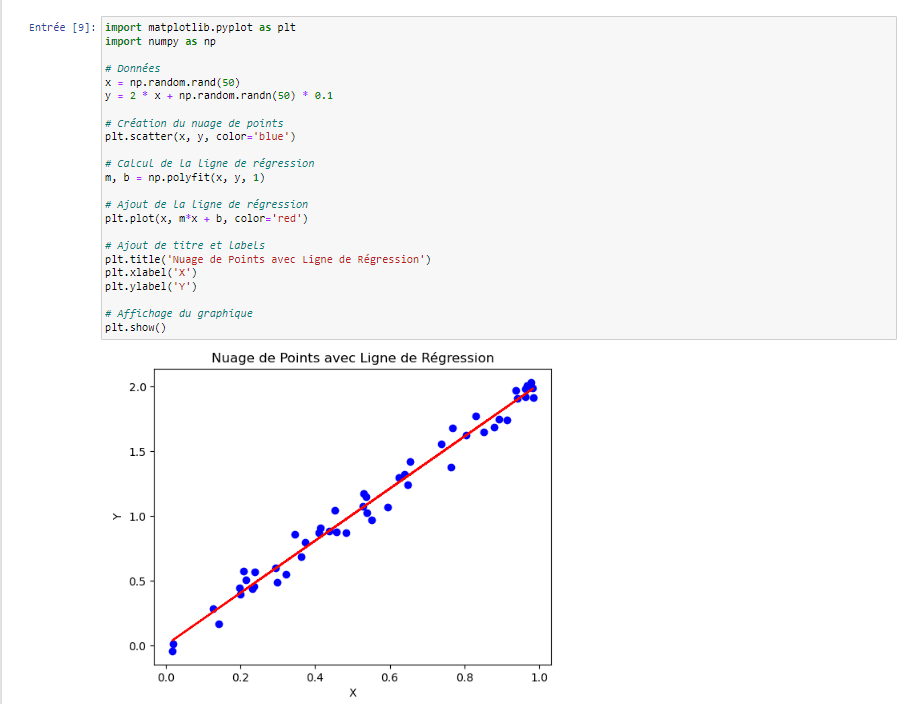
5.Boîtes à moustaches :
import matplotlib.pyplot as plt
import numpy as np
# Données
data = np.random.normal(0, 1, 100)
# Création de la boîte à moustaches
plt.boxplot(data)
# Ajout d’étiquettes
plt.xlabel(‘Données’)
plt.ylabel(‘Valeurs’)
plt.title(‘Boîte à moustaches’)
plt.show()
Les boîtes à moustaches sont utiles pour montrer la distribution et l’étendue d’une variable continue. Elles sont particulièrement utiles lorsque vous souhaitez montrer les quartiles, la médiane et les valeurs aberrantes. Exemple :
6.Cartes :
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.io.shapereader as shpreader
# Création de la carte
ax = plt.axes(projection=ccrs.PlateCarree())
ax.set_extent([-180, 180, -90, 90])
# Ajout des frontières
shpfilename = shpreader.natural_earth(resolution=’110m’, category=’cultural’, name=’admin_0_countries’)
countries = shpreader.Reader(shpfilename)
for country in countries.geometries():
ax.add_geometries([country], ccrs.PlateCarree(), facecolor=’none’, edgecolor=’black’)
# Ajout d’étiquettes
plt.title(‘Carte’)
plt.show()
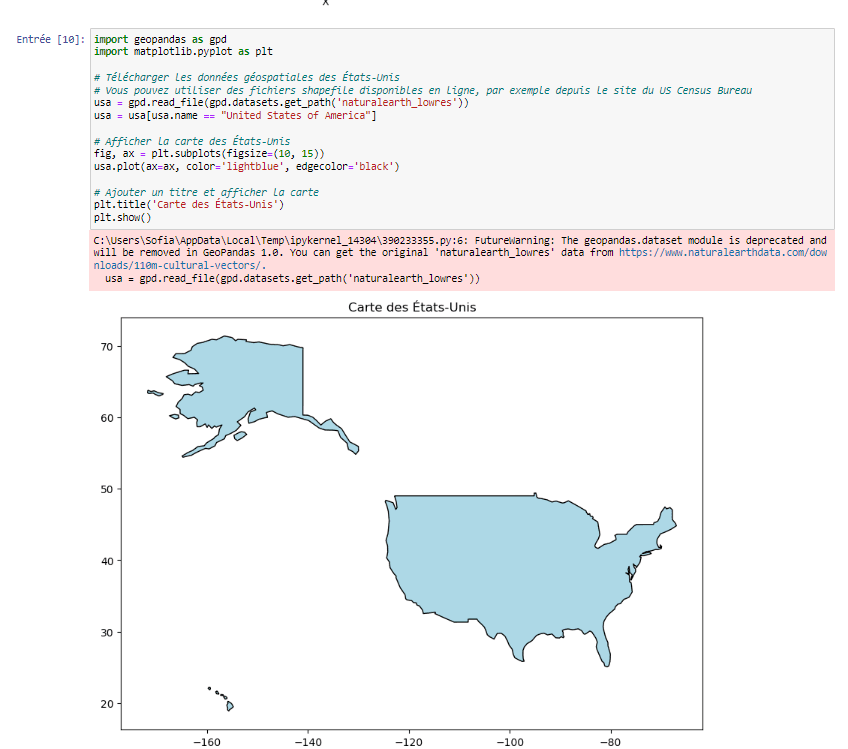
Les cartes sont utiles pour montrer la distribution géographique d’une variable. Elles sont particulièrement utiles lorsque vous souhaitez montrer des données spatiales ou des données géographiques.
N.B : Assurez-vous d’avoir installé les bibliothèques nécessaires avec pip install geopandas matplotlib contextily et cartopy si vous voulez gênerez des cartes.
Attention : Cartopy a plusieurs dépendances, y compris GEOS, Proj, et Shapely, qui sont généralement gérées automatiquement lors de l’installation via pip. Cependant, dans certains cas, surtout sur Windows, vous pourriez avoir besoin d’installer des packages supplémentaires ou des binaires pour ces dépendances.7.Lignes :
import matplotlib.pyplot as plt
import numpy as np
# Données
x = np.linspace(0, 10, 100)
y = np.sin(x)
# Création de la ligne
plt.plot(x, y)
# Ajout d’étiquettes
plt.xlabel(‘x’)
plt.ylabel(‘y’)
plt.title(‘Ligne’)
plt.show()
Les lignes sont utiles pour montrer l’évolution d’une variable au fil du temps. Elles sont particulièrement utiles lorsque vous souhaitez montrer des tendances ou des modèles temporels. Exemple :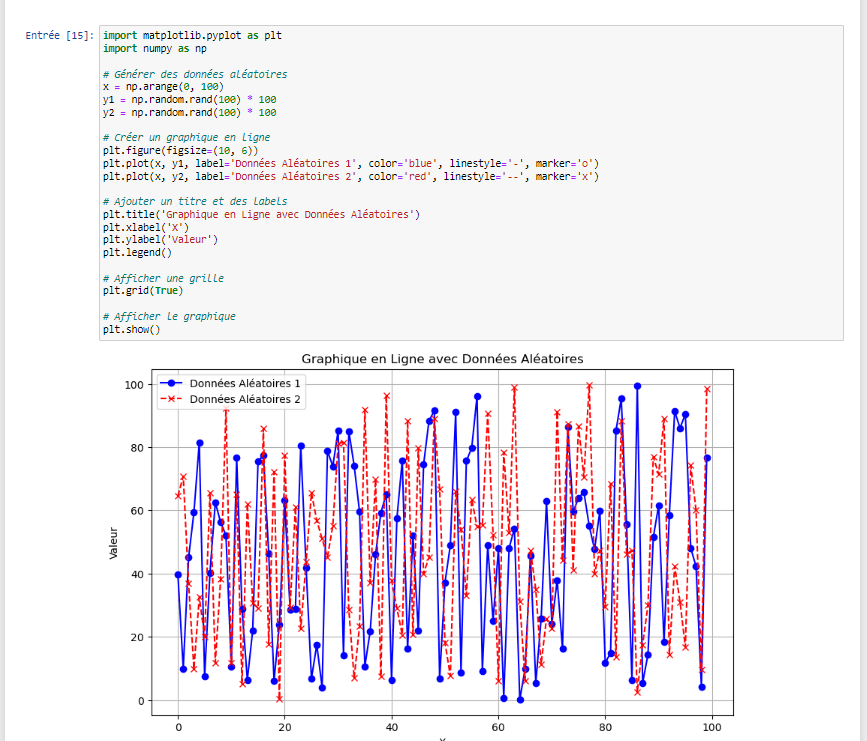
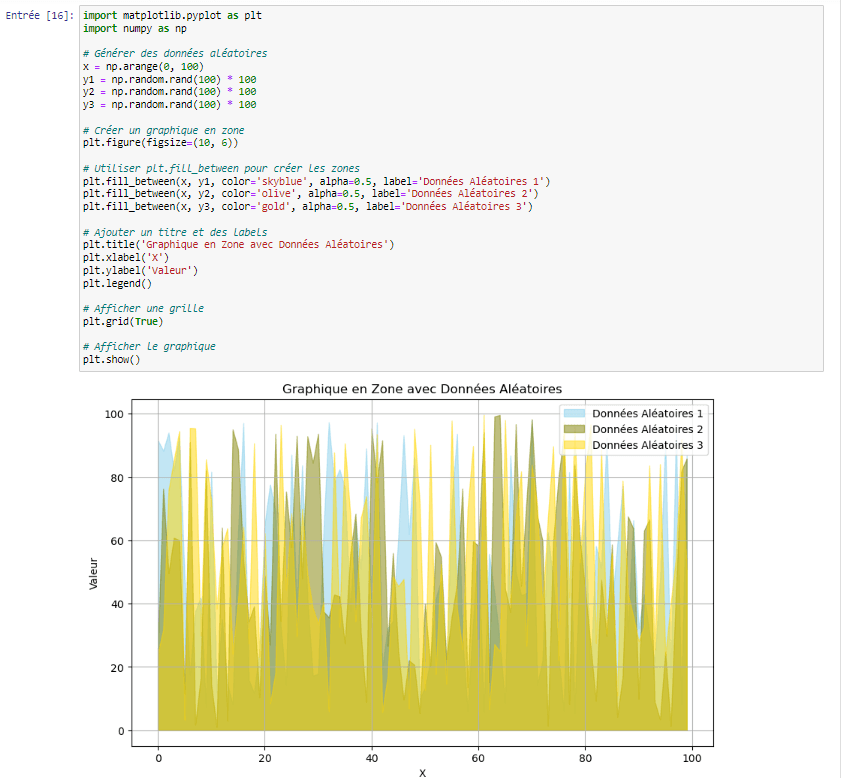
8.Areas :
import matplotlib.pyplot as plt
import numpy as np
# Données
categories = [‘Catégorie 1’, ‘Catégorie 2’, ‘Catégorie 3’]
values = [50, 30, 20]
# Création de l’area
plt.axes().fill_betweenx(np.arange(len(categories)), values, alpha=0.5)
plt.bar(categories, values)
# Ajout d’étiquettes
plt.xlabel(‘Catégories’)
plt.ylabel(‘Valeurs’)
plt.title(‘Area’)
plt.show()
Les areas sont utiles pour montrer la contribution relative de différentes catégories à une variable continue. Elles sont particulièrement utiles lorsque vous souhaitez montrer la répartition d’une variable continue selon des catégories.
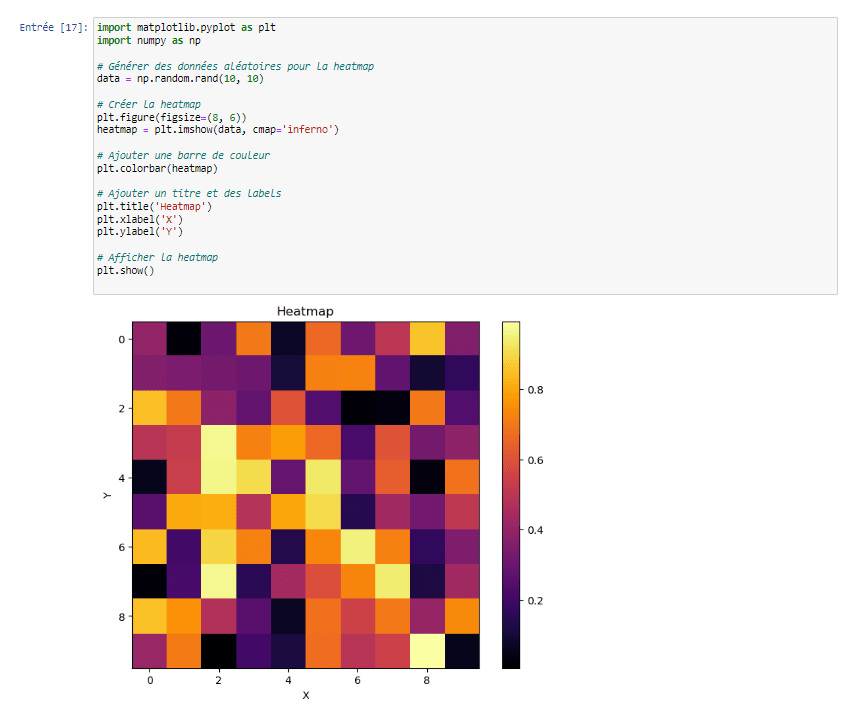
9.Heatmaps :
import matplotlib.pyplot as plt
import seaborn as sns
# Données
data = sns.load_dataset(‘flights’)
# Création de la heatmap
sns.heatmap(data.pivot_table(values=’passengers’, index=’month’, columns=’year’))
# Ajout d’étiquettes
plt.title(‘Heatmap’)
plt.show()
Les heatmaps sont utiles pour montrer la corrélation ou la relation entre deux variables continues. Elles sont particulièrement utiles lorsque vous souhaitez montrer des relations complexes entre des variables.
Il est important de choisir le type de visualisation approprié en fonction de vos données et de votre message. Il est également important de tenir compte de la taille et de la complexité de vos données, ainsi que de votre public cible. Enfin, il est important d’utiliser des couleurs et des symboles appropriés pour aider votre public à comprendre votre visualisation.
A vous de jouer : Utilisez l’interface python de votre choix.
Types of Visualizations and When to Use Them
Here is a list of some common types of visualizations, along with examples of code to generate them using the Python library Matplotlib.
How to Install Matplotlib?
On Python:
- Open your command prompt or terminal.
- Type the following command:
pip install matplotlib - Press Enter and wait for the installation to complete.
On Anaconda:
- Open the Anaconda command prompt or terminal.
- Type the following command:
conda install matplotlib - Press Enter and wait for the installation to complete.
After installing Matplotlib, you can start coding. Here are some codes to use for visualization in Python. Personally, I will use Jupyter Notebook via Anaconda.
1. Bar charts:
import matplotlib.pyplot as plt
# Data
categories = [‘Category 1’, ‘Category 2’, ‘Category 3’]
values = [50, 30, 70]
# Create the chart
plt.bar(categories, values)
# Add labels
plt.xlabel(‘Categories’)
plt.ylabel(‘Values’)
plt.title(‘Bar chart’)
plt.show()
Bar charts are useful for comparing discrete values. They are especially useful when you want to highlight differences between categories or groups.
Example, from my Jupyter interface:
2. Pie charts:
import matplotlib.pyplot as plt
# Data
categories = [‘Category 1’, ‘Category 2’, ‘Category 3’]
values = [50, 30, 20]
# Create the pie chart
plt.pie(values, labels=categories)
# Add labels
plt.title(‘Pie chart’)
plt.show()
Pie charts are useful for showing the proportions of a whole. They are especially useful when you want to show the distribution of a categorical variable.
3. Histograms:
import matplotlib.pyplot as plt
import numpy as np
# Data
data = np.random.normal(0, 1, 1000)
# Creating the histogram
plt.hist(data)
# Adding labels
plt.xlabel(‘Values’)
plt.ylabel(‘Frequency’)
plt.title(‘Histogram’)
plt.show()
Histograms are useful for showing the distribution of a continuous variable. They are particularly useful when you want to show the frequency or density of the data.
Example:
4. Scatter plots:
import matplotlib.pyplot as plt
import numpy as np
# Data
x = np.linspace(0, 10, 100)
y = np.sin(x)
# Create the scatter plot
plt.scatter(x, y)
# Add labels
plt.xlabel(‘x’)
plt.ylabel(‘y’)
plt.title(‘Scatter plot’)
plt.show()
Scatter plots are useful for showing the relationship between two continuous variables. They are especially useful when you want to show the correlation or trend between two variables.
Example:
5. Box plots:
import matplotlib.pyplot as plt
import numpy as np
# Data
data = np.random.normal(0, 1, 100)
# Create the box plot
plt.boxplot(data)
# Add labels
plt.xlabel(‘Data’)
plt.ylabel(‘Values’)
plt.title(‘Box plot’)
plt.show()
Box plots are useful for showing the distribution and range of a continuous variable. They are especially useful when you want to show quartiles, the median, and outliers.
Example:
6 Maps:
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.io.shapereader as shpreader
# Creating the map
ax = plt.axes(projection=ccrs.PlateCarree())
ax.set_extent([-180, 180, -90, 90])
# Adding borders
shpfilename = shpreader.natural_earth(resolution=’110m’, category=’cultural’, name=’admin_0_countries’)
countries = shpreader.Reader(shpfilename)
for country in countries.geometries():
ax.add_geometries([country], ccrs.PlateCarree(), facecolor=’none’, edgecolor=’black’)
# Adding labels
plt.title(‘Map’)
plt.show()
Maps are useful for showing the geographical distribution of a variable. They are particularly useful when you want to show spatial data or geographical data.
Note: Make sure you have installed the necessary libraries with pip install geopandas matplotlib contextily and cartopy if you want to generate maps.
Attention: Cartopy has several dependencies, including GEOS, Proj, and Shapely, which are generally managed automatically during installation via pip. However, in some cases, especially on Windows, you might need to install additional packages or binaries for these dependencies.
Example:
Maps are useful for showing the geographic distribution of a variable. They are especially useful when you want to show spatial data or geographic data.
N.B.: Make sure you have installed the necessary libraries with pip install geopandas matplotlib contextily and cartopy if you want to generate maps.
Warning: Cartopy has several dependencies, including GEOS, Proj, and Shapely, which are usually handled automatically during pip installation. However, in some cases, especially on Windows, you may need to install additional packages or binaries for these dependencies.
7.Lignes :
import matplotlib.pyplot as plt
import numpy as np
# Données
x = np.linspace(0, 10, 100)
y = np.sin(x)
# Création de la ligne
plt.plot(x, y)
# Ajout d’étiquettes
plt.xlabel(‘x’)
plt.ylabel(‘y’)
plt.title(‘Ligne’)
plt.show()
Lines are useful for showing how a variable changes over time. They are especially useful when you want to show trends or patterns over time. Example:
8.Areas :
import matplotlib.pyplot as plt
import numpy as np
# Données
categories = [‘Catégorie 1’, ‘Catégorie 2’, ‘Catégorie 3’]
values = [50, 30, 20]
# Création de l’area
plt.axes().fill_betweenx(np.arange(len(categories)), values, alpha=0.5)
plt.bar(categories, values)
# Ajout d’étiquettes
plt.xlabel(‘Catégories’)
plt.ylabel(‘Valeurs’)
plt.title(‘Area’)
plt.show()
Areas are useful for showing the relative contribution of different categories to a continuous variable. They are particularly useful when you want to show the distribution of a continuous variable across categories.
9.Heatmaps :
import matplotlib.pyplot as plt
import seaborn as sns
# Données
data = sns.load_dataset(‘flights’)
# Création de la heatmap
sns.heatmap(data.pivot_table(values=’passengers’, index=’month’, columns=’year’))
# Ajout d’étiquettes
plt.title(‘Heatmap’)
plt.show()
Heatmaps are useful for showing the correlation or relationship between two continuous variables. They are especially useful when you want to show complex relationships between variables.
It is important to choose the right type of visualization based on your data and message. It is also important to consider the size and complexity of your data, as well as your target audience. Finally, it is important to use appropriate colors and symbols to help your audience understand your visualization.
Your turn: Use the python interface of your choice.